แปล PDF เป็น 100+ ภาษา — คอลัมน์ ตาราง และฟอนต์คงเดิม
วางไฟล์ PDF เลือกภาษาเป้าหมาย และดาวน์โหลด PDF ที่เหมือนต้นฉบับ — มีเพียงคำที่เปลี่ยนไป เราใช้การลบข้อความเดิมออกแล้วเขียนคำแปลเข้าไปใหม่ พร้อมการฝังฟอนต์บางส่วน ทำให้คอลัมน์ ตาราง และลิงก์คงอยู่ครบถ้วน
ลากและวางไฟล์ PPT, Word (.docx) หรือ PDF ที่นี่ หรือคลิกเพื่อเลือก
ทดลองใช้ฟรี · ไม่ต้องลงทะเบียน · ไม่ต้องใช้บัตรเครดิตสูงสุด 100 MB · ไฟล์จะถูกลบภายใน 24 ชั่วโมงใช้งานทุกวันสำหรับเอกสารวิชาการ สัญญา รายงานการวิจัย คู่มือ และเอกสารข้อมูลผลิตภัณฑ์
No file handy? See live samples →Translated. Still looks like the original.
Two real PDFs run through TransKeep — Apple's Q2 financial statements and the paper that started modern AI. Scroll the original on the left, the translation on the right, and inspect the result: every column, table cell, footnote and formula stays in its exact original position.
Borderless shadow tables, dense financial columns, multi-column footnotes — numbers stay aligned to the digit.
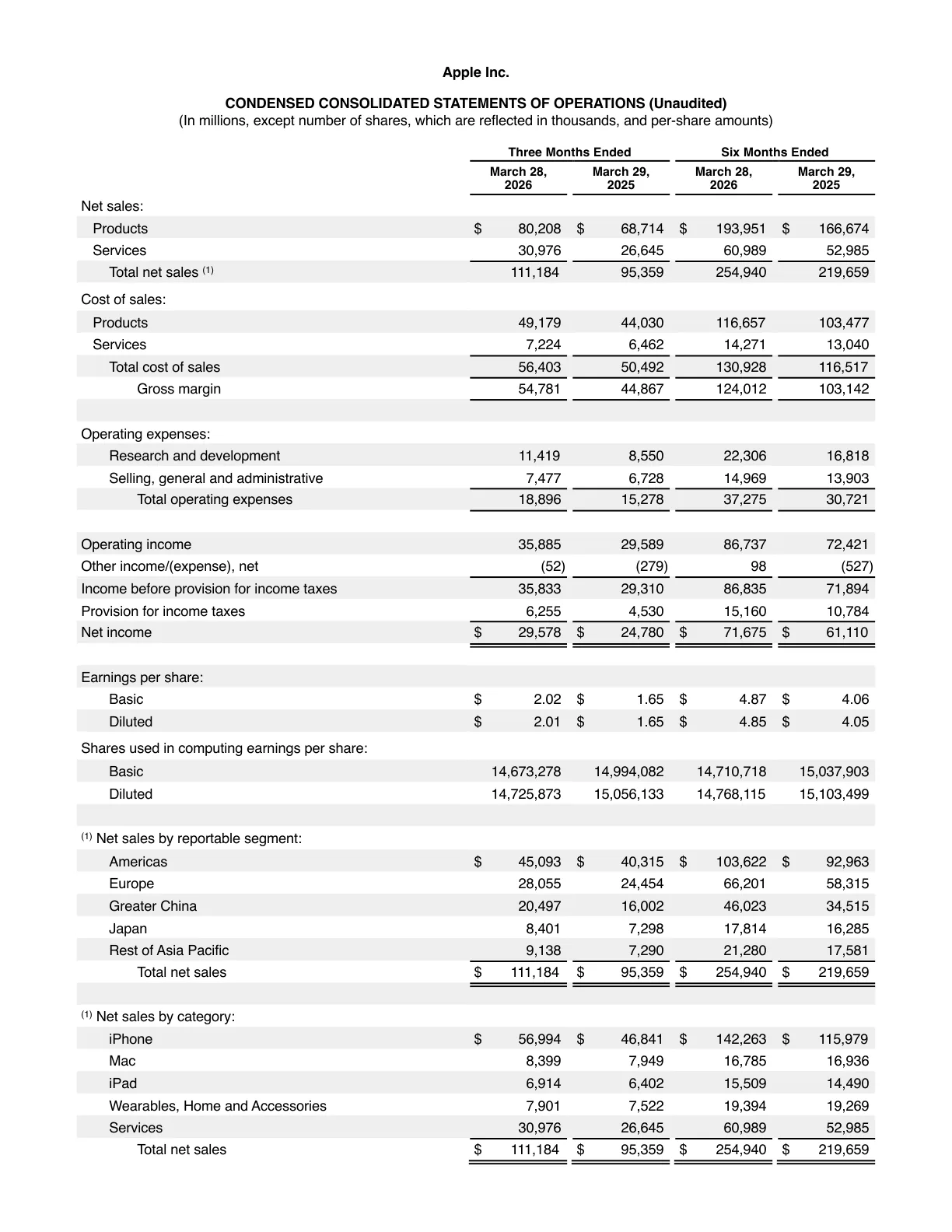
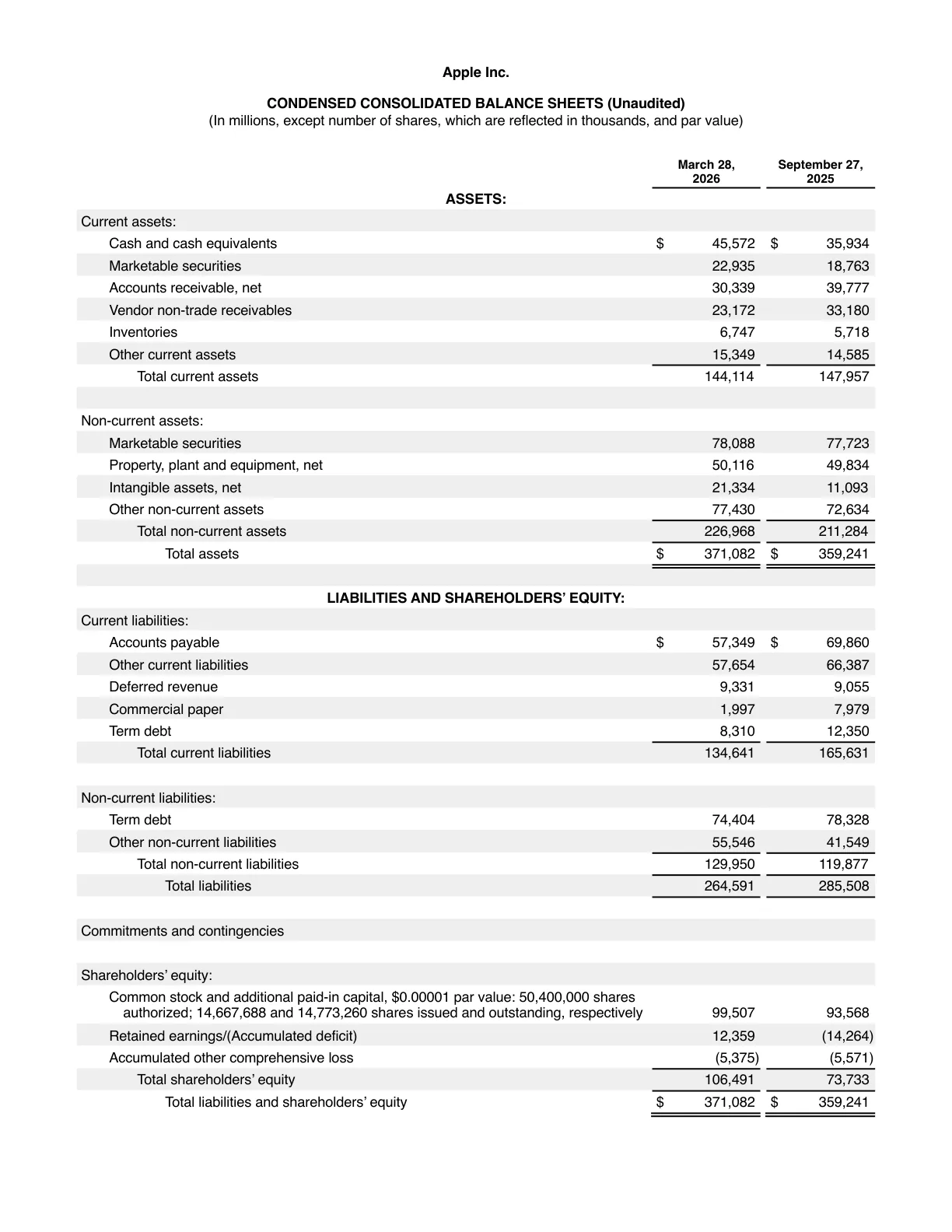
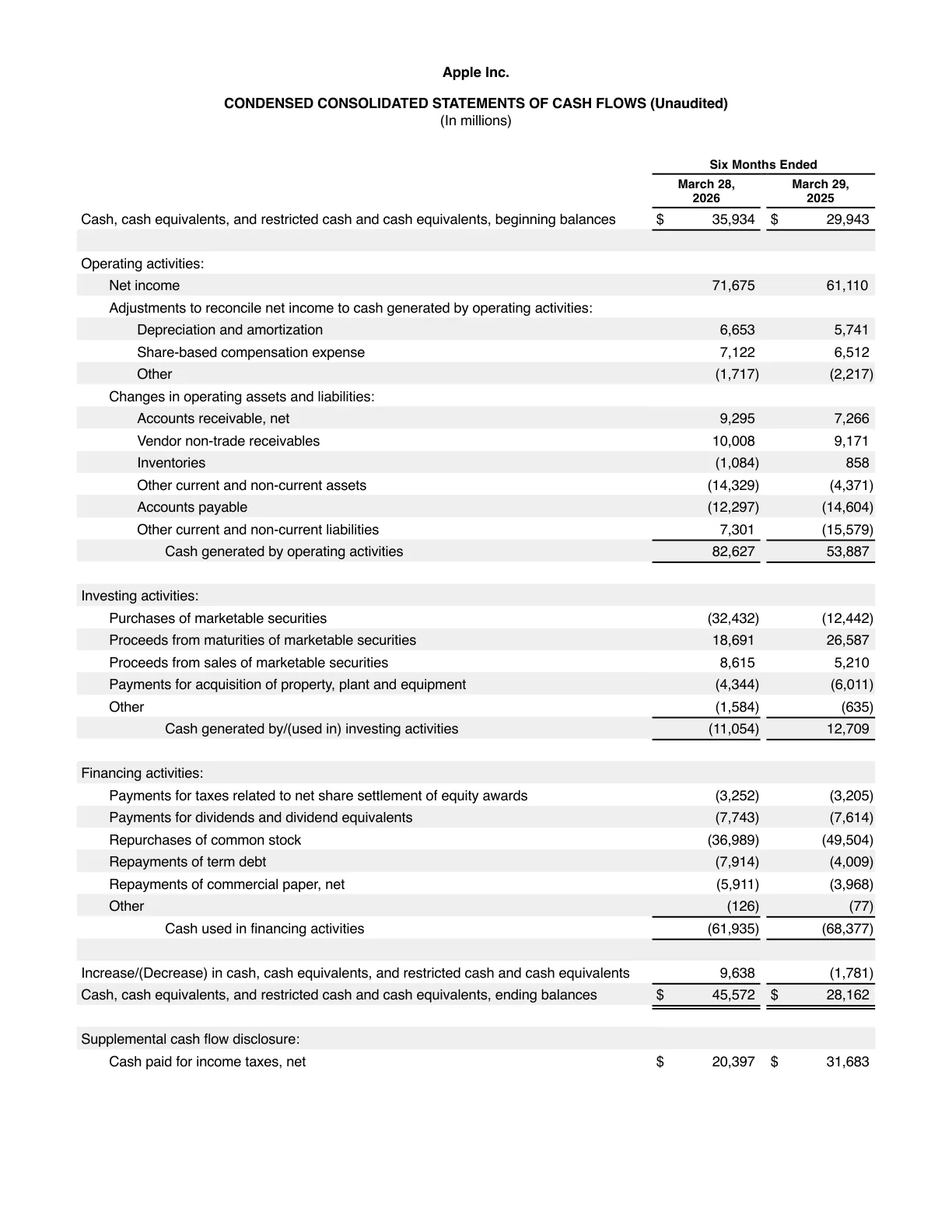
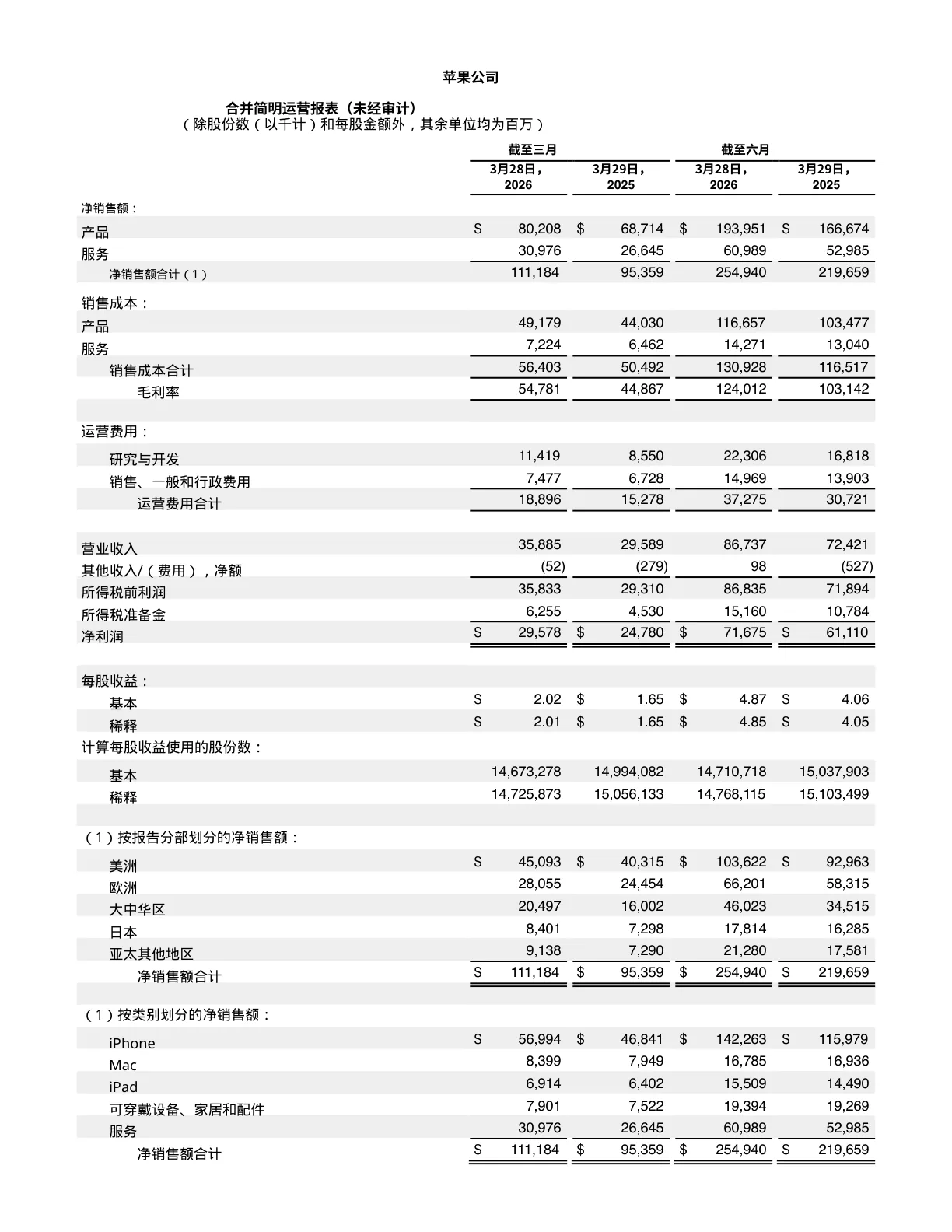

เหตุผลที่การแปล PDF มีความยากเป็นพิเศษ
PDF ไม่มีต้นฉบับ — นักแปลต้องจัดรูปแบบใหม่ทั้งหมด
เครื่องมือส่วนใหญ่จะดึงข้อความออกมาแล้วส่งไปยัง Word ทำให้สูญเสียคอลัมน์ ตาราง เชิงอรรถ และลิงก์เดิมไป PDF ที่แปลแล้วต้องจัดรูปแบบใหม่ทั้งหมดก่อนจึงจะใช้งานได้
เค้าโครงหลายคอลัมน์พัง
รายงานสองคอลัมน์ เค้าโครงนิตยสาร และบทความวิชาการ กลายเป็นข้อความคอลัมน์เดียว ตารางถูกฉีกขาด แผนภูมิและรูปภาพสูญเสียคำอธิบายประกอบ
ฟอนต์หายไปในสคริปต์ที่ไม่ใช่ละติน
การแปลเป็นภาษาจีน ญี่ปุ่น เกาหลี หรืออาหรับ มักจะแสดงเป็นสัญลักษณ์สี่เหลี่ยม (□) เพราะฟอนต์ใน PDF เดิมไม่มีอักขระเหล่านั้น คุณต้องฝังฟอนต์ใหม่ด้วยตนเอง
สร้างขึ้นเพื่อ PDF โดยเฉพาะ
การลบข้อความเดิมออกแล้วเขียนทับ
เราจะลบข้อความเดิมออกแล้วเขียนคำแปลเข้าไปในตำแหน่งเดิมทุกประการ — ทุกคอลัมน์ เซลล์ตาราง และเชิงอรรถ จะยังคงอยู่ที่ตำแหน่งเดิม
การฝังฟอนต์บางส่วนอัตโนมัติ
แปลเป็นภาษา CJK, อาหรับ, ฮีบรู หรือไทย? เราจะฝังเฉพาะอักขระที่คุณต้องการจากฟอนต์ที่เหมาะสมกับสคริปต์เท่านั้น เพื่อให้ผลลัพธ์แสดงผลได้อย่างสมบูรณ์แบบทุกที่
ลิงก์คงอยู่
ลิงก์ที่คลิกได้ทั้งหมดใน PDF เดิมจะถูกกู้คืนหลังจากการแปล ข้อความแสดงผลจะถูกแปล URL ปลายทางจะยังคงอยู่
ผลลัพธ์ PDF ดั้งเดิม
ดาวน์โหลด PDF จริง — ไม่ใช่ภาพสแกน ไม่ใช่เอกสาร Word สามารถค้นหา คัดลอก พร้อมส่งให้ลูกค้า ผู้มีอำนาจกำกับดูแล หรือทีมของคุณได้ทันที
TransKeep เทียบกับวิธีการแปล PDF อื่นๆ
| TransKeep | เครื่องมือแปลทั่วไป | การแปลด้วยตนเอง | |
|---|---|---|---|
| เค้าโครงหลายคอลัมน์ | คงเดิม 100% | ยุบเหลือคอลัมน์เดียว | จัดรูปแบบใหม่ด้วยตนเอง |
| ตารางและแผนภูมิ | คงเดิมในตำแหน่ง | ฉีกขาด | สร้างใหม่ด้วยตนเอง |
| ลิงก์ | กู้คืนทั้งหมด | สูญหาย | สร้างลิงก์ใหม่ด้วยตนเอง |
| ฟอนต์ CJK / RTL | ฝังฟอนต์บางส่วนอัตโนมัติ | อักขระสี่เหลี่ยม (□) | ต้องค้นหาฟอนต์ |
| รูปแบบผลลัพธ์ | PDF ดั้งเดิมที่ค้นหาได้ | ส่งออกเป็น Word .docx | ส่งออกใหม่ด้วยตนเอง |
| เอกสาร 100+ หน้า | ประมวลผลต่อเนื่อง | แครชหรือตัดทอน | ใช้เวลาหลายวัน |
ใครใช้ TransKeep สำหรับ PDF
กฎหมายและการปฏิบัติตามข้อกำหนด
แปลสัญญา NDA และเอกสารยื่นเรื่องต่อหน่วยงานกำกับดูแล พร้อมคงหมายเลขข้อ ความหมายเลขเชิงอรรถ และส่วนลงนามไว้เหมือนเดิมทุกประการ
การวิจัยและวิชาการ
แปลเอกสารวิชาการ วิทยานิพนธ์ และบทความวารสาร พร้อมคงเค้าโครงสองคอลัมน์ การอ้างอิง และคำอธิบายประกอบรูปภาพไว้
การเขียนผลิตภัณฑ์และเทคนิค
แปลคู่มือ เอกสารข้อมูล และ SOP โดยไม่ต้องจัดรูปแบบตาราง แผนภาพ หรือลำดับเลขขั้นตอนใหม่
รายงานทางการเงินและนักลงทุน
แปลรายงานประจำปี หนังสือชี้ชวน และเอกสารนำเสนอ — ทุกตาราง คำอธิบายประกอบแผนภูมิ และเชิงอรรถยังคงอยู่ครบถ้วน
คำถามที่พบบ่อยเกี่ยวกับการแปล PDF
PDF ที่มีข้อความทุกประเภท เช่น รายงาน สัญญา เอกสารทางวิชาการ คู่มือ โบรชัวร์ สไลด์ที่ส่งออกเป็น PDF ไม่รองรับ PDF ที่สแกนจากรูปภาพเท่านั้น (OCR อยู่ในแผนงาน)
ใช่ เราใช้การปกปิดข้อมูลในตำแหน่งเดิม ดังนั้นแต่ละบล็อกข้อความจะถูกเขียนใหม่ในตำแหน่งเดียวกับต้นฉบับ คอลัมน์ ตาราง ส่วนหัว ส่วนท้าย และรูปภาพทั้งหมดจะยังคงอยู่ที่เดิม
เราจะทำการ subset และฝังฟอนต์ที่เหมาะสมกับสคริปต์โดยอัตโนมัติ (เช่น Noto Sans CJK, Noto Sans Arabic) เพื่อให้ PDF ที่แปลแล้วแสดงผลได้อย่างสมบูรณ์แบบ แม้ว่าเอกสารต้นฉบับจะไม่มีอักขระสำหรับภาษาเป้าหมายก็ตาม
ใช่ หลังจากปกปิดข้อมูลแล้ว เราจะกู้คืนคำอธิบายประกอบลิงก์เดิมทั้งหมด ข้อความที่แสดงจะถูกแปล; URL ปลายทางจะยังคงอยู่
ผลลัพธ์ที่ได้คือ PDF ที่เป็นต้นฉบับ ค้นหาได้ คัดลอกได้เต็มที่ และพร้อมสำหรับเครื่องมือดาวน์สตรีม สำหรับการแก้ไขเชิงลึก เราขอแนะนำให้เปิดในโปรแกรมแก้ไข PDF
การถ่ายโอนทั้งหมดเข้ารหัสด้วย SSL/TLS ไฟล์จะถูกลบโดยอัตโนมัติภายใน 24 ชั่วโมง เราไม่เคยใช้เนื้อหาของคุณเพื่อฝึกโมเดล AI